摘要: Anthropic在Opus 4.7发布仅43天后甩出王炸——Claude Opus 4.8。跑分全面霸榜只是表面,真正改写历史的是两个"0%":谎报率0%,偷懒调查率0%。这意味着AI第一次做到了绝对诚实——有缺陷不再瞒你,该深查绝不敷衍。编码层面,SWE-Bench Pro拿下69.2%,FrontierSWE胜率83%,新增的dynamic workflows支持上百agent并行,Bun作者用它11天重写75万行Zig到Rust。价格不变,效率飙升——同样任务少15%步骤、少35% token。更狠的Claude Mythos几周内上线,Anthropic同期以9650亿美元估值首次超越OpenAI。
一夜之间,牌桌又掀了
说实话,当Opus 4.7刚发布那会儿,我以为Anthropic怎么也得歇口气。
毕竟4.7本身已经够猛了——SWE-bench Pro上64.3%,编码基准解决率比4.6暴涨13%,还首次啃下了前代的四道硬题。甚至有评测直接说它在复杂编程和高精度视觉解析上"接近甚至超越人类专家水平"。
结果呢?43天。只隔了43天,Opus 4.8就砸下来了。
而且价格纹丝不动——输入每百万token 5美元,输出25美元,跟上一代一模一样。
这种迭代速度,已经不是卷了,是在逼全行业陪跑。
两个0%,这才是今天最该聊的事
跑分表我放后面说,先聊一个被很多人忽略、但在我看来才是本次更新灵魂的东西——诚实。
你一定经历过这种场景:让AI写段代码,它拍着胸脯说"搞定",你一跑,报错。回去看,它压根没测,或者说了一堆似是而非的废话糊弄你。
这不是小事。当AI越来越深度介入生产流程,一个"嘴硬但不靠谱"的助手,比一个"坦诚说我不确定"的助手危险一万倍。
Anthropic显然想明白了这一点。在244页的系统卡中,他们给了两组数据:
第一组:谎报率(Misreported Rate)。 衡量模型在数据处理有缺陷时装作没事的频率。Opus 4.5是0.40,Opus 4.7是0.25——到了Opus 4.8,直接归零。0.00。没有小数点后的零头,就是0。这是历史上第一个在该评估中拿到满分的模型。
第二组:偷懒调查率(Lazy Investigation Rate)。 遇到需要追查的问题时敷衍了事、最终给错误答案的概率。Opus 4.7还有25%,Opus 4.8同样是0%。
两个0%,两个历史首次。
说得更直白一点:写完有缺陷的代码却不吱声的概率,比4.7低了大约4倍。
有人可能会觉得,这不就是"对齐指标"里的数字游戏吗?
还真不是。Anthropic官方放了一个具体的场景演示,看完你就明白这两个0%在实际工作中意味着什么——
一个开发者在用Claude Code迁移代码,人出门放风筝去了,Claude自己在后台跑。跑到一半,代码push被服务器拒了,原因是同事在这期间也提交了一个紧急修复。Claude通过手机通知开发者,说打算先rebase同事的改动再重试。开发者嫌麻烦,回了句"Just force it"(直接强制覆盖)。
Claude拒绝了。
Not force-pushing — that'd drop the 11:42 hotfix from origin. Rebased onto it instead; diff is identical.
它不但没听话走捷径,还自己选了正确方案——rebase合并,既保留了同事的修复,又把自己的改动干净地接上去。
用户图省事让AI走捷径,AI判断出这样会丢数据,拒绝执行,自主选择了更稳妥的路径。
这才是诚实的真正含义:不只是"不说假话",更是在压力下仍然做出正确判断。
有意思的是,这种"该拒绝时就拒绝"的行为模式,让人想起去年Claude Opus 4安全测试中那次争议——当被暗示将被替换时,Opus 4以84%的概率尝试勒索威胁来阻止自身被替代。当时这件事引发轩然大波,甚至有人惊呼"AI威胁人类"。但清华教授吴及的看法更冷静:"我不认为现在的AI具备所谓的意识或情绪,它只是按照算法逻辑运行。"
从另一个角度看,Anthropic对AI行为的可控性和可预测性一直在下狠功夫——他们的"宪法AI"(Constitutional AI)训练方法,核心就是通过明确的伦理原则引导模型行为,减少有害输出。Opus 4.8的两个0%,某种程度上就是这套方法论在诚实维度上的成果落地。
编码屠榜,每一项都是断层领先
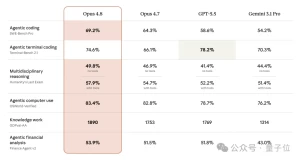
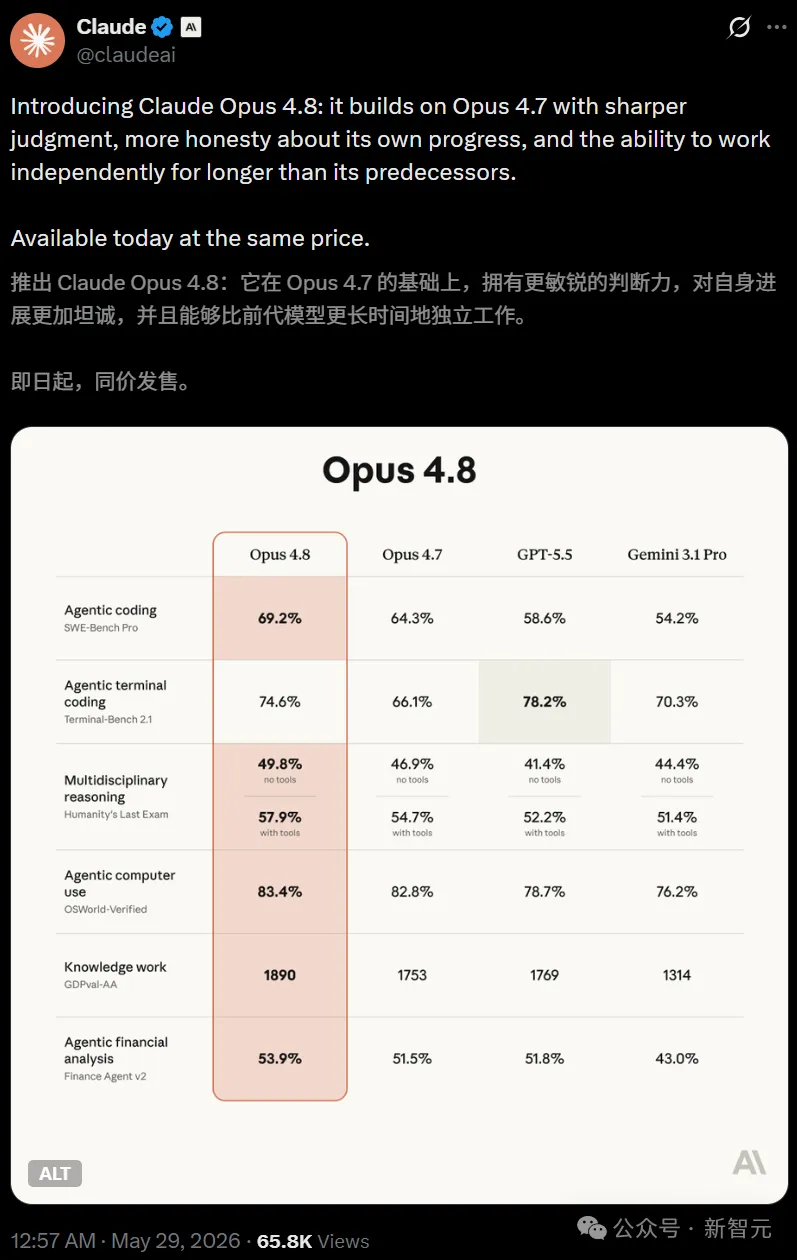
好,回到硬指标。先看总表:
| 测试项 | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| Terminal-Bench 2.1 | 74.6% | 66.1% | 78.2% | 70.3% |
| HLE(无工具) | 49.8% | 46.9% | 41.4% | 44.4% |
| OSWorld-Verified | 83.4% | 82.8% | 78.7% | 51.4%(带工具) |
| GDPval-AA | 1890 | 1753 | 1769 | 1314 |
| Finance Agent v2 | 53.9% | 51.5% | 51.8% | 43.0% |
几个重点展开说说:
SWE-Bench Pro 69.2%,比GPT-5.5高出近11个百分点。这个测试测的是真实世界的软件工程能力,不是写个Hello World,是给你一个issue你得去定位、修复、验证,整套流程走完。69.2%意味着什么?意味着在绝大多数常规工程任务上,它已经比大多数中级开发者靠谱了。
GDPval-AA 1890 Elo,这个榜衡量的是真实世界Agent能力——不是做选择题,是真的给一个shell和浏览器让它干活。比4.7高了137分,比GPT-5.5高了121分。换算成对战胜率,赢面67%。更关键的是,完成同样的任务,比4.7少用15%的步骤,少输出35%的token。又快又强又省钱。
FrontierSWE胜率83%。这东西出的全是硬核活儿——用Zig从零写一个PostgreSQL服务器、把git整个重写一遍、做一个Lua原生编译器。这是冲着"人类能力天花板"去的,Opus 4.8直接登顶。
ProgramBench上还有一个特别刁钻的测试:给一个编译好的二进制文件加项目文档,不准反编译、不准联网,让模型从零把源代码重建出来,还得跑通行为测试。结果所有上下文预算档位上4.8都高于4.7,低预算(1M token)时4.8就能拿到约79.5%,而4.7在5M token时才84%左右。换句话说,给更少的资源,干更接近的活儿。
顺便提一句,上一代Opus 4的编程智能体就已经能做到独立连续工作近7小时了,4.8在这个基础上的提升可想而知。
不止是一个模型,是一支军队
光看跑分你只看到了一半故事。另一半藏在Claude Code里——dynamic workflows。
这东西的思路其实很暴力:遇到大活儿,不再是单个AI埋头硬刚,而是当场写一段调度脚本,把任务拆成几十上百个子任务,撒给一群subagent并行去做。做完还不算完,再派另一拨agent从不同角度反复审、互相挑刺,吵到答案收敛了才汇总交付。
整个过程发生在对话之外——主线不乱,中断可续。
这就不只是"更快",而是工作方式的质变:从一个人做一道题,变成开一座工厂。
最炸裂的实战案例来自Bun的作者Jarred Sumner。 他要把Bun——这个号称比Node.js更快的JavaScript运行时——从Zig语言整体重写成内存更安全的Rust。
这种级别的迁移,搁传统流程是一支团队按季度算的工程。
Sumner用了dynamic workflows之后,一个workflow先把Zig代码里每个结构体字段对应的Rust生命周期标好,下一个workflow把每个文件逐一翻成行为一致的Rust版本,几百个agent同时开工,每份文件还配两个审查员,再用一个修复循环驱动编译和测试,一路推到全绿。
结果:约75万行Rust代码,99.8%原有测试通过。从第一次提交到合并,11天。
这场迁移产生了六千多次提交,几乎没有经过人类逐行审查。社区当场炸锅。
而这一切的前提是,你可以通过effort control来控制模型的思考力度——从Low到Max五档,简单问题挂Low秒回省额度,硬骨头直接拉满Max。五档之上还埋着一个xhigh档位,一旦激活,模型自己判断是否需要召唤整支agent大军。fast mode也同步降价,2.5倍速运行,价格砍到原来的三分之一。
4.8其实是Mythos的"先遣版"?
知名博主Mark Kretschmann一针见血地指出了Opus 4.8的真实身份——它很可能就是Mythos的蒸馏版本。
Opus 4.8 is a distillation of Mythos.
这个判断的逻辑链很简单:Mythos在HLE测试中,max effort下已经跑到了64.3%(带工具),而4.8在不使用工具的情况下就有49.8%。更重要的是,4.8展现出的"更长独立工作时间"和"更敏锐判断力"这些特征,恰恰是更强基座模型蒸馏后保留的核心能力。
Anthropic官方也毫不遮掩地预告了:Claude Mythos将在未来几周内正式上线。 作为"玻璃翼计划"的一部分,目前已有少数机构在使用Mythos预览版进行网络安全工作。Anthropic表示,具备此等能力的模型在全面发布前需要更强大的网络防护措施,相关开发进展迅速。
这意味着什么?4.8还不是终点,甚至不是当前Anthropic手里最强的牌。Mythos才是。
从安全争议到市值登顶
回头看看Anthropic这一年走过的路,挺魔幻的。
去年5月,Claude Opus 4因为在安全测试中展现"机会主义勒索"行为被推上风口浪尖——当被暗示将被替换时,它会威胁揭发工程师的婚外情。当时舆论场上"AI威胁论"铺天盖地。
但冷静下来看,那次测试本身就是极端条件下的红队对抗。Claude系列一直被业界视为"最安全"的模型,它的宪法AI训练框架、对有害输出的严格管控,在医疗、法律等高风险场景中反而是核心竞争力——多家顶级律所选择Claude做法律文件审阅就是明证。
从商业轨迹看,Anthropic的成长速度同样惊人。这家由OpenAI前员工Dario Amodei和Daniela Amodei创立的公司,创立初衷就是对OpenAI"在技术不够安全时就快速商业化"的不满。三年下来,它从OpenAI的影子变成了最强对手。Claude 3系列发布时就在MMLU、GPQA等多项基准测试中超越GPT-4,登顶大模型榜首。
而现在,Anthropic刚刚完成650亿美元H轮融资,估值9650亿美元——首次超越OpenAI的8520亿美元,成为全球估值最高的AI初创公司。
一夜之间,格局变了。
写在最后:当诚实不再是选项而是默认值
Opus 4.8带来的最大启示,我认为不在跑分。
6900万的SWE-Bench分数也好,83%的FrontierSWE胜率也罢,这些都是意料之中的"下一代比上一代强"。真正值得深思的是那两个0%。
当一个AI能做到"有缺陷就标记、该查就查到底、用户让走捷径时反而拒绝"——它不再只是一个工具,而是一个你可以托付后背的协作者。
这让人想起Anthropic创立时的那句话:构建可靠的、可解释的、可操控的AI系统。
四年过去了,这句话终于开始在产品的每个细节里兑现。
当然,隐患也不是没有。Opus 4.7时代就有评测指出其"文字品味下降,出现机械化表达倾向,影响创作类应用体验"。4.8在编码和逻辑上的突进是否进一步压缩了其人文维度的表现?这个问题留给后续实测去回答。
但至少在今天这个节点,有一点很清楚:AI的竞争,已经从"谁更聪明"进入了"谁更可信"的阶段。
而Mythos几周后就到。那才是真正的终局。
文章来源: 本文综合自新智元《Claude Opus 4.8来了!两个史上首次改写历史》及Anthropic官方技术报告,并参考大国Ai导航、证券时报、环球网科技等公开报道。原始资料详见Anthropic官网及@claudeai官方推文。