摘要:Anthropic连夜扔出了Claude Opus 4.8,表面看是跑分例行上涨,实则藏着四件事:动态工作流拉起几百个子Agent并行干活、幻觉率砍到前代的1/4、思考控制权还给用户、API支持中途插系统指令。更狠的是,Mythos级别模型几周后就解禁——那个一个月挖出一万多个高危漏洞的怪物。本文从实测数据、功能拆解、竞品对比三个维度,讲清楚Opus 4.8到底值不值得你现在切过去。
一、跑分:稳着涨,但有一个科目被GPT-5.5反杀了
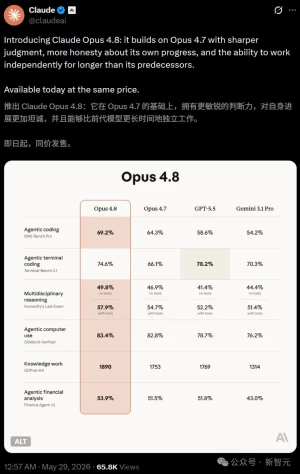
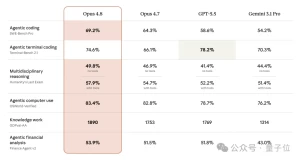
先说大家最关心的数字。Opus 4.8这次没有搞什么跨代飞跃,但胜在全面向上,而且有几个数据确实拉开了差距:
| 测试项目 | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro(编程智能体) | 69.2% | 64.3% | 58.6% | 54.2% |
| Humanity's Last Exam(不带工具) | 49.8% | — | — | — |
| Humanity's Last Exam(带工具) | 57.9% | — | 52.2% | 51.4% |
| OSWorld-Verified(桌面操作) | 83.4% | 82.3* | 78.7% | — |
| Online-Mind2Web(浏览器智能体) | 84% | — | 低于4.8 | — |
| GDPval-AA(知识工作) | 1890 | 1753 | — | — |
| Finance Agent v2(金融分析) | 53.9% | — | 51.8% | — |
| Terminal-Bench 2.1(终端编程) | 74.6% | 66.1% | 78.2% | 70.3% |
编程赛道SWE-Bench Pro领先GPT-5.5足足10.6个百分点,这在编码智能体领域算相当大的身位了。桌面操作和浏览器自动化的成绩也很硬核,尤其是OSWorld-Verified拿了83.4%,超过GPT-5.5的78.7%。还有个冷门但值得提的:Opus 4.8是第一个在Legal Agent Benchmark全通过率上突破10%的模型,这领域之前一直被吐槽"合格率个位数"。
但是,Terminal-Bench 2.1这项翻车了。Opus 4.8拿到74.6%,GPT-5.5是78.2%,直接反超。更扎心的是,GPT-5.5换上自家的Codex CLI框架后能飙到83.4%。所以在纯命令行环境里敲命令、查日志、改配置这种活儿,GPT-5.5暂时还是更猛。
怎么理解这种差异?后文细聊。
二、诚实度:这次不说"安全",说"不骗你"
每次Anthropic发模型都要讲安全,但这次话锋转了——主打"诚实"。
这背后是一个非常具体的痛点:以前的AI在做编程或者复杂任务时,经常"假装完成"。代码跑不通、逻辑有漏洞,它照样给你一份自信满满的总结,让你以为活干完了,结果一跑全是bug。
Opus 4.8在这件事上做了专项优化:
代码存在缺陷却"悄悄放行"的概率,降到了Opus 4.7的1/4
它会主动标出自己拿不准的地方,不硬编一个看着合理的答案糊弄你
遇到计划明显不合理的时候,它敢直接说"不",而不是默默照办
Anthropic对齐团队的量化评估也很有意思——"未对齐行为"(Misaligned behavior)打分,越低越好。Opus 4.8拿到1.83,远低于Opus 4.7的2.48,已经逼近内部对齐天花板Claude Mythos Preview的1.78。对齐团队的原话是:Opus 4.8在"支持用户自主权、为用户最大利益着想"这些亲社会特质上,达到了当前新高。
来自一线工程师的评价比跑分更实在。Shopify的Staff工程师Tom Pritchard说:"Opus 4.8在Claude Code里会问对的问题,抓住自己的错误,在计划不靠谱时直接拒绝,在摸清复杂的多服务探索任务后才敢下重手改动。这是一个能真正拿来构建的模型。" 而某公司CTO Kay Zhu透露,在他们内部的Super-Agent基准上,Opus 4.8是唯一一个端到端完成所有案例的模型,同等成本击败了前代Opus和GPT-5.5。
说实话,一个模型变强的同时还能变得更让人放心,这比多考几分难多了。
三、动态工作流:几百个Agent同时干活,Token绞肉机来了
这大概是Opus 4.8整个发布里最具想象力的东西。
**动态工作流(Dynamic Workflows)**目前在Claude Code里以研究预览版上线,核心逻辑是:你丢一个大任务进去,Claude先动态拆解计划,然后把工作分发给几百个并行的子Agent同时处理,每个子Agent的结果都要经过验证才会汇入最终答案。
更骚的是,它还会派出对抗性Agent,专门去推翻已有结论,持续迭代到答案收敛。整个过程的进度实时保存,中途中断了能从断点接着跑,不用从头来过。
真实案例:Bun从Zig移植到Rust
Bun的作者Jarred Sumner用动态工作流干了这么一件事——把整个Bun运行时从Zig语言移植到Rust。涉及约75万行Rust代码,从第一次提交到合并只用了11天,现有测试套件通过率99.8%。
具体操作是这样的:
第一个工作流把Zig代码里每个结构体字段对应的Rust生命周期全部梳理清楚
下一个工作流让几百个并行子Agent逐文件完成移植,每个文件还配了两个审查Agent
再跑一个修复循环,把构建和测试全部跑通
移植完成后又跑了一个通宵的工作流,专门处理不必要的数据拷贝,为每个问题各自开了PR等人最终review
这搁以前得拆成无数个小任务串行喂给它,现在可以一口气交给模型来完成。
触发方式也很简单,直接跟Claude Code说"create a workflow"就行,或者在努力值菜单里开启ultracode设置,它会自动判断什么时候该用工作流。
但有件事必须说清楚:动态工作流消耗的token量远超普通Claude Code会话。 Anthropic自己也建议先拿范围明确的小任务试水,搞清楚用量再上大任务。第一次触发工作流时,Claude Code会显示即将运行的内容并请求确认。
目前该功能对Max、Team和Enterprise计划开放,Enterprise默认关闭需要管理员手动开启。
四、思考控制权还给了用户,Fast模式便宜了三倍
Effort Control回来了。
Opus 4.7搞了个自适应思考(Adaptive Thinking),让模型自己判断什么时候该深度思考。很多人不喜欢,因为你根本不知道它到底有没有认真想,额度本身又贵[^原创]。Opus 4.8把默认努力度拉回high,同时把控制权还给了用户。
在claude.ai和Cowork的模型选择器旁边,你现在可以直接调一个滑块:调高,Claude想得更频繁、更深入;调低,回答更快,速率限制消耗也更小。默认是high,官方认为这是质量和体验的最佳平衡点。碰到硬骨头还有extra(xhigh)和max两档可以拉满。
Fast模式降价了。 Opus 4.8的fast模式速度是普通版的2.5倍,定价为输入每百万token 10美元、输出50美元——比上一代fast模式的$30/$150便宜了三分之二。注意,比的是上一代fast mode,不是比标准模式便宜,所以还是超贵。常规用量定价不变:输入5美元/输出25美元每百万token。
Databricks的CTO Hanlin Tang给出的数字是:Opus 4.8在他们agentic推理任务上,单token成本比Opus 4.7低了61%。能力涨了,单位成本反而降了。
还有个小变化:Opus 4.6被下架了。
五、API小升级:中途插系统指令,不断缓存
这改动不大,但对重度用API的开发者来说是实打实的便利。
以前用Messages API,本质上发的是一串对话记录,系统规则通常放在最前面。任务跑到一半想改规则、调权限、换环境上下文,要么重新组织一大段prompt,要么绕到用户消息里补充,缓存也很容易被冲掉[^原创]。
Opus 4.8这次支持了在messages数组中中途插入system条目,不用打断prompt cache就能更新指令。这对于跑长时间Agent任务的开发者来说,终于不用为了改个权限就把整个对话重来一遍了。
六、Claude vs GPT:终端敲命令还是跨文件协作?
如果你是Claude和GPT双持用户,怎么选?
从跑分来看,Terminal-Bench 2.1是个关键分水岭。Opus 4.8在纯命令行环境里74.6%,GPT-5.5是78.2%,换成Codex CLI更是83.4%。
但这不是简单的谁强谁弱的问题。GPT-5.5更像老工程师——给它一个明确任务,让它敲命令、查日志、改配置、跑脚本,它非常猛。Opus 4.8更像一个能读完整个项目的协作型工程师——它适合看懂一个已有项目,再跨很多文件一点点改,最后把一个长任务推进完[^原创]。
Devin团队的反馈印证了这个判断:"Opus 4.8使用工具干净利落,遵循指令的一致性完全能满足我们自主工程负载长时间无人值守运行的需求。它改进了Opus 4.6的表现,并且修正了我们在Opus 4.7上看到的注释啰嗦、工具调用异常等问题。"
选哪个,取决于你的核心场景是单点执行还是全局协作。
七、Mythos倒计时:几周后见
最后一个大新闻藏在公告末尾:Mythos要来了。
前情回顾一下。Claude Mythos Preview是目前Anthropic能力最强的模型,此前只开放给了少数组织做网络安全任务。在过去一个月里,这个模型帮从各种知名软件中找出了一万多个高危或严重漏洞。Mythos在SWE-bench Verified上拿到了93.9%,专家级CTF任务成功率73%,能跑通32步企业网络攻击模拟的3/10,83%的已知漏洞能一次复现并写出可用PoC——包括OpenBSD一个存在27年的漏洞。
正因为这种能力,Anthropic此前一直把它限制在Project Glasswing联盟内部(约40家组织,含AWS、Apple、Microsoft、Google等),仅用于防御性安全研究。
但现在态度变了。Anthropic表示正在为Mythos构建更强的网络安全防护体系,预计未来几周内就能向所有客户开放。同时还在开发一批能力接近Opus、但成本更低的模型。
有评论认为Opus 4.8可能是"Mythos之前的最后一个Opus系列模型"。不管怎么说,Anthropic的节奏肉眼可见地在加快——4月发Opus 4.7,一个多月后就推出4.8,比此前泄露代码暗示的发布时间还提前了。
说不定就蹲着GPT-5.6来狙击呢。
Opus 4.8今天全平台可用,API模型标识为claude-opus-4-8,定价与前代一致。
有新模型用就是好啊,熬夜也不困了。
文章来源:
Anthropic官方公告:anthropic.com/news/claude-opus-4-8
卡尔的AI沃茨《多Agent/Mythos/降幻觉,Claude Opus4.8来了》
网易订阅《Opus 4.8编码力横扫多项基准,终端测试却被GPT-5.5反杀?》
网易订阅《Claude Opus 4.8 发布|Mythos 即将上线》
腾讯新闻《Claude Opus 4.8来了,没什么大颠覆,重点是:Mythos将于几周内发布》
腾讯新闻《突发!Claude Opus4.8发布:超大规模项目稳定输出有谱了,Mythos级别模型几周后见》
腾讯新闻《比剧透提前!Anthropic发布Claude Opus 4.8》
搜狐《Anthropic Claude Opus 4.8发布:性能提升,Mythos几周内发布》
CSDN《Anthropic 五月动态盘点:Opus 4.7、Mythos Preview 与 Agent SDK 计费拆分》