摘要:Opus 4.8表面看只是几个百分点的benchmark提升,但实际上藏着Anthropic的三步棋——还4.7的债、用post-training快速迭代狙击竞品、以及最重要的一步:通过Dynamic Workflows把AI编程的单位从"一个任务"切换成"一个下午"。Fast Mode降价3倍是给大企业留人的,Terminal-Bench那个坑是故意没补的,Karpathy加入Anthropic大概率看中的就是这条路。这不是一次小版本升级,是Anthropic在agentic coding赛道上的一次明牌。
一个"小更新"为什么值得写这么多?
凌晨刷到Anthropic发Opus 4.8的时候,我的第一反应跟HN上大多数人一样——"看起来像是个挺小的更新?"
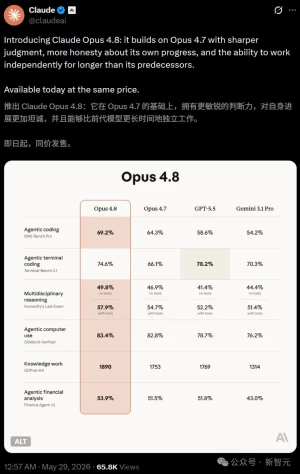
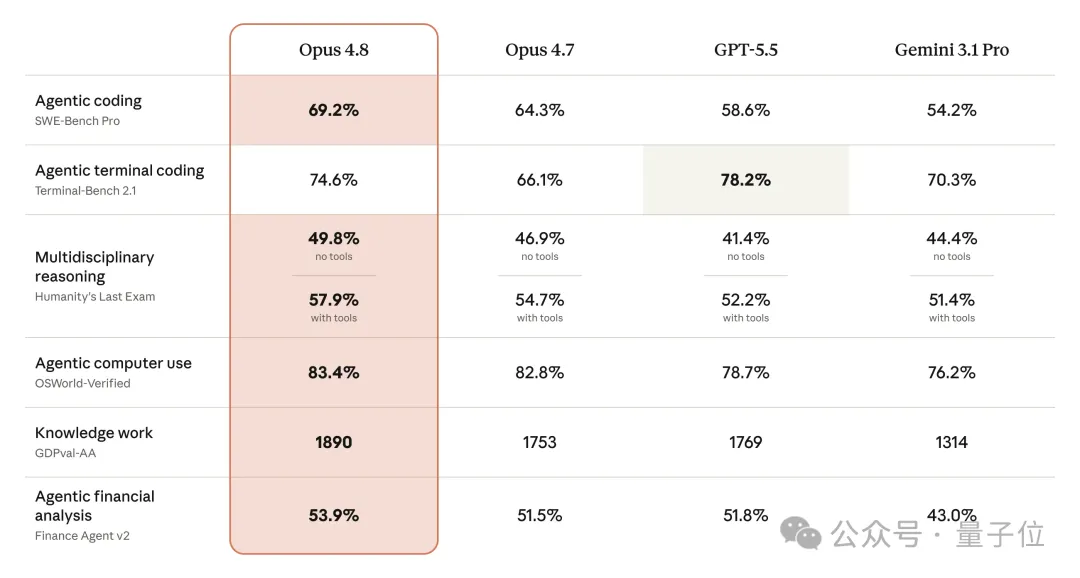
SWE-Bench Pro从64.3到69.2,OSWorld从82.8到83.4,就这?
但我把官方博客、Dynamic Workflows专页、Fast Mode文档全翻了一遍之后,我发现这事儿根本不是benchmark上那几个百分点的事。
先说结论:Opus 4.8是Anthropic在换一种方式跟开发者打交道。 以前你用Claude的单位是"一句话"或"一个任务",4.8想悄悄把单位换成"一下午"——你说一声,它自己拆出几百个并行subagent跑两个小时,回来给你一个能合并的PR。
这才是真正值得聊的东西。
一、4.7欠的债,4.8在还
先交代一个时间线:Opus 4.7是4月16日发的,4.8是5月28日发的,中间只隔了41天。
大模型行业之前的发版节奏是半年起步,Anthropic自己也从来没这么快过。41天赶一版同价升级,这不叫产品迭代,这叫救火。
4.7当时翻了什么车?Reddit上那条"Opus 4.7 is not an upgrade but a serious regression"的帖子拿了2300多赞,X上一条说"4.7没比4.6进步"的帖子1.4万赞。HN上这次4.8的讨论区里一堆人说当时被4.7那个adaptive reasoning气到直接切回4.6。TechCrunch的报道也不客气,直接说4.8的快速发布就是因为"chilly reception to Opus 4.7"。
所以你看4.8的官方博客,三条还债写得明明白白:
第一,手动effort控制加回来了。 4.7搞了个"adaptive reasoning",让模型自己判断要不要深度思考。听起来很美好对吧?实际体验是你让它认真想的时候它偷懒,你让它快回的时候它磨叽。4.8直接默认effort拉到high,档位还给用户——你说了算。
第二,写代码不那么瞎自信了。 以前的Claude给你一段代码,里面有问题它不告诉你。现在它会自己标出来哪儿可能有坑。官方包装成"降4倍幻觉",社区有人吐槽说把这叫"honesty"提升是过度拟人化。说实话两边都对,但对开发者来说拿到的是实打实的好处——至少不用我自己一行行review它偷偷埋的雷了。
第三,价格不变。 还是$5输入/$25输出。老用户其实不需要什么花哨的营销话术,稳定的迭代加上不涨价,就够了。
二、41天发版背后的节奏狙击术
41天这个数字值得单独拿出来说。
Anthropic首席产品官Mike Krieger之前就说过,Opus的升级标志着公司战略转向"更频繁的渐进式改进,而非仅专注重大版本更新"。当时听着像场面话,4.8这次是真落地了。
但41天能训一个大模型吗?显然不能。这里有个关键细节:Opus 4.7和4.8的training data cutoff都是2026年1月,完全一样。 而Opus 4.6还是May 2025。
这说明什么?4.7到4.8这41天,base model大概率没有重做大规模预训练,迭代的全是post-training——RLHF、safety训练、tool-use微调这些东西。这才是Anthropic能做到"频繁切片发版"的真正原因:base model复用,post-training快速迭代。
对比一下,国内DeepSeek V4发布时预训练语料截止时间要早不少,国内厂商想做快速迭代更多卡在"卡和数据"上。Anthropic这套打法,本质上是在post-training阶段做敏捷开发。
而且4.8这个时间点,刚好卡在GPT-5.6传言发布之前。所以它不只是"还4.7的债",同时也是一杆有意切出来的中间态产品——我手上压着比公开模型水平高一截的天花板,需要狙击的时候切一片出来就行。这种打法你在芯片厂商那边见过,在大模型这边是新的。
晚cutoff还有个更隐蔽的二阶价值:cutoff越晚,模型对"AI能做什么、自己作为AI coding agent能做什么"的自我认识越准。 它见过最新版Claude Code的文档,见过最新的MCP和skill规范,见过别人怎么用agentic方式编程。你跟它聊best practice、说"按你自己的方式想",它能接得住。新手友好的核心机制其实是这个,跟模型本身"聪不聪明"关系反而没那么大。
三、Fast Mode降价3倍的真相——不是给你的
Fast Mode这事儿大部分中文报道都讲错了,我得掰清楚。
官方原文是"fast mode for Opus 4.8—where the model can work at 2.5× the speed—is now three times cheaper than it was for previous models"。
"3倍便宜"是相对自家上一代的Fast Mode,不是相对标准模式。
| 项目 | 输入价 | 输出价 |
|---|---|---|
| Opus 4.6/4.7 Fast Mode(旧) | $30/百万token | $150/百万token |
| Opus 4.8 Fast Mode(新) | $10/百万token | $50/百万token |
| Opus 4.8 标准模式(参照) | $5/百万token | $25/百万token |
Fast Mode还是比标准模式贵2倍,跟自己的上一代比才是1/3的价格。
看你用哪种方式接入就知道了——我自己用Claude Code是订阅档,Fast Mode用不起也用不上。Fast Mode真正的客户是API接入的大企业:几十个工程师每天上千次API调用Claude Code,账单完全是另一个量级。
之前甚至有消息说微软要求员工停止使用Claude Code,原因就是公司报销的API账单肉疼。这种背景下Anthropic主动砍Fast Mode价格到三分之一,目的非常清楚:留住大企业客户,不让他们因为成本压力流失到GPT-5.5那边去。
Anthropic在第三方部署这块一直很重视模型版本固定的问题——通过Bedrock、Vertex AI部署Claude Code时,如果不固定模型版本,当Anthropic发布新模型时,账户未启用新版本的用户会无声中断。企业客户要的是稳定和可预测的成本,Fast Mode降价本质上是在回应这个诉求。
对个人开发者来说,订阅档依然是最划算的方式。Fast Mode这次的降价红包,主要不是发给我们的。
四、Dynamic Workflows——这次发布的真正炸弹
跟着4.8一起发的Dynamic Workflows,才是这次最值得深挖的东西。
它做的事很简单也很疯狂:你跟Claude Code说一句"create a workflow",或者打开ultracode这个新设置,剩下的事它自己安排。Anthropic自己的描述是"Claude can plan the work and then run tens to hundreds of parallel subagents in a single session"。
举个具体例子:你说"把这100万行Java迁到Kotlin",然后你出去喝杯咖啡。回来的时候它已经自己拆出了几百个小agent——一个负责改文件结构,一个负责改语法,一个负责跑测试,一个专门挑前三个的毛病。两小时后你看到的不是一段代码,是一个能合并的PR。
我自己手上的对照实验
我平时用Claude Code跑女娲.skill(一个把人物蒸馏成思维skill的工具)的时候,已经在手动让它spawn好几个独立subagent做盲测——一个agent扮演评委审风格,一个扮演读者打分,互相质疑"这段是不是太AI腔了""这个洞察立得住吗"。
但我能搭起来的subagent数量上限大概十几个,因为再多我自己脑子里就管不过来了。Dynamic Workflows是让Claude自己写orchestration脚本,subagent数量到几百,自带adversarial verification机制。原来我手动管十几个,现在Claude自己管几百个。
Bun rewrite:最极端的案例
Bun把Zig写的运行时迁移到Rust,用Claude Code的Dynamic Workflows,11天产出大概75万行Rust代码。
这事儿在HN上有正经的争议。产生了13000多个unsafe block,主流声音是"这不算可以直接上production的代码"。但即便你把它当成"一个需要review的草稿PR"来看——一个AI在11天内产出能编译、能跑测试的75万行Rust,已经完全不在原来的量级里了。
回想一下,去年Claude 4 Opus刚发布的时候,Rakuten的测试数据就说通过Opus 4开发的编程智能体可独立稳定连续工作7小时,当时已经打破了OpenAI的纪录。现在Dynamic Workflows把"连续工作"升级成了"并行协作",从时间维度的突破变成了规模维度的突破。
Karpathy看到的可能就是这条路
Karpathy上周刚加入Anthropic当MTS。他过去几年一直在讲一件事:一个研究员真正的杠杆,是他能调动多少compute、多少agent。 从他在OpenAI做RLHF、到自己写nanoGPT教程、到Eureka,一脉相承的判断都是:未来超级个体的形态,是一个人指挥一群AI。
Dynamic Workflows就是把这个杠杆做成了产品。
一个人,一台电脑,跑几百个并行subagent,11天产出75万行代码。这不是"企业级工具",这是Karpathy这种人想要的形态——给我一个人,但让我能像一个200人团队那样工作。
当然,社区里有人吐槽token消耗暴涨,Anthropic自己的文档也承认这玩意儿会比普通Claude Code session贵得多。它不是给个人开发者每天用的,是给企业里那个"要把100万行legacy code迁到新语言"的工程总监用的。
但从更长远的视角看,随着词元成本持续下降——中国日均词元调用量已经从2024年的1000亿飙升到2026年一季度的140万亿,9.9元就能买到1000万tokens——Dynamic Workflows的使用门槛只会越来越低。
五、Terminal-Bench那个故意没补的坑
说完优点,说一个有趣的例外。
Opus 4.8在agentic维度几乎全赢,但有一项叫Terminal-Bench 2.1——GPT-5.5是78.2%,Opus 4.8是74.6%,差了3.6个百分点。
Anthropic自己在官方博客脚注里默认了这事。他们用的是Terminus-2公开harness,承认GPT-5.5在自家Codex CLI harness下能跑到83.4%。
41天的补丁包,为什么不去补这个坑?
两种解释。一种是Anthropic在选不同的山头,把宣传重点放在Super-Agent、Legal Agent Benchmark、Online-Mind2Web、SWE-Bench Pro这些自己擅长的方向。另一种更冷酷——模型架构在纯ops/CLI能力上确实有结构性短板,41天补不出来。
我觉得真相在中间。无论故意还是没办法,Anthropic用资源分配清楚地表态了:
GPT-5.5的优势:纯终端、ops、CLI工作流,给ChatGPT在Codex里跑命令用
Opus 4.8的优势:理解既有代码库、多文件改动、长链路agent execution,给Cursor、Claude Code这种IDE-style的agent用
"我擅长的方向赢得彻底"比"每个benchmark都打"更聪明。
(顺便提醒一句:Anthropic公布的SWE-Bench Pro 69.2%、OSWorld 83.4%这些数字,都是他们自家harness跑的,不能直接和公开榜对齐。回顾一下,Opus 4.1在SWE-Bench Verified上的成绩是74.5%,那是公开基准,数字不能混着比。)
写在最后:工程师的新定位
作为一个每天大概12小时挂在Claude Code上的人,我的判断是:对个人开发者来说,Opus 4.8稳赢——同价格、写代码不那么瞎自信了、默认effort high、手动控制权也回来了。如果你用Cursor、Claude Code、Cline,今天就切到4.8。
Fast Mode不用纠结,订阅档够用。
我自己最想试的是Dynamic Workflows。下次跑女娲.skill的时候,我打算不再自己想清楚开几个subagent、谁审谁、互相怎么质疑。直接说"create a workflow",然后去吃个饭。
如果它想得比我好,那就是Anthropic在自家Agentic Coding Trends Report里说的那句话的真实样子:
"Engineer's job shifts from writing code to coordinating agents that write code."
工程师的工作,正在从写代码,变成协调写代码的agent。
这不是某个遥远的未来。这就是现在。