Claude Code,你的 AI 编程搭档
Claude Code 是 Anthropic 推出的 Agentic Coding 工具,住在你的终端里,能读懂整个代码库、读写文件、跑命令、自动提交 PR,用自然语言就能把开发任务从“说需求”推进到“可上线代码”。

Claude Code 官网介绍
Claude Code 是 Anthropic 推出的 Agentic Coding 系统,核心定位是“住在终端里的 AI 编程搭档”,而不是传统的代码补全插件。它可以直接读取你的整个代码库,跨文件进行修改、运行测试、执行 Git 操作,并自动验证结果,形成“收集上下文 → 采取行动 → 验证结果”的完整代理循环。
Claude Code 的核心优势包括:
1、项目级全局理解:能一次性加载数十万甚至上百万行代码,理解模块依赖、架构和项目约定,而不仅仅是当前文件。
2、自主执行与代理循环:可以自主规划多步修改、读写文件、执行 Shell 命令、运行测试,失败时自动调整方案,直到任务完成。
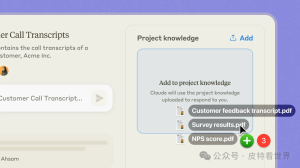
3、终端原生与工具链深度集成:直接在终端或 IDE 中运行,与 Git、CI/CD、构建工具等零距离对接,真正“手伸进项目里干活”。4、多智能体与 MCP 生态扩展:支持主 Agent + 子 Agent 并行协作,通过 MCP 协议接入 GitHub、Slack、数据库等外部工具,构建可编排的智能体工作流。
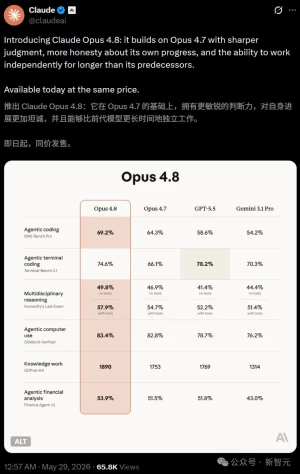
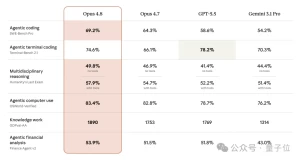
在功能演进方面,Claude Code 已从单纯的编码助手升级为面向工程化的 Agentic Coding 平台。2025–2026 年间,Anthropic 持续引入 CLAUDE.md 项目记忆、Skills 技能库、MCP 工具协议、Sub-agent 并行任务以及 Dynamic Workflows 等能力,使 Claude Code 能承接从需求拆解、代码实现、安全审查到自动提交 PR 的全流程任务,并在 SWE-bench Verified 等基准测试中达到 80%+ 的自主问题解决率。
目前,Claude Code 的最新功能已向 Pro、Team 及企业版用户开放,并持续与 GitHub、JetBrains、VS Code 等开发工具深度整合,覆盖终端、IDE、桌面应用和网页版等多端场景,帮助个人开发者和团队把更多精力放在架构决策与产品思考,而不是重复性编码与命令操作上。